





 "
" Сегодня команда разработчиков с гордостью объявляет о новом улучшении SubQuery, функции индексирования SubQuery.
Словарь индексации SubQuery - это ускоритель ваших проектов. Он значительно улучшает индексацию производительности вашего проекта SubQuery, иногда делает ее в 10 раз быстрее. При индексации данных цепочки проекты SubQuery делали проверку каждого блока. Цепь Polkadot - это большой блокчейн весом более чем 130 ГБ неструктурированных данных, находящихся на 6 миллионах блоков. Процесс проверки занимает много часов, время, которое вы не хотите ждать, особенно при тестировании. Проекты SubQuery теперь имеют возможность пропустить все это, разработчики, по сути, предварительно индексируют местоположение всех событий в цепочке.
Производительность повышается больше всего, когда данные не представляются в стандартном виде, а являются цепочкой индексов. Словарь пропускает больше блоков, и, следовательно, влияние на производительность становится больше.
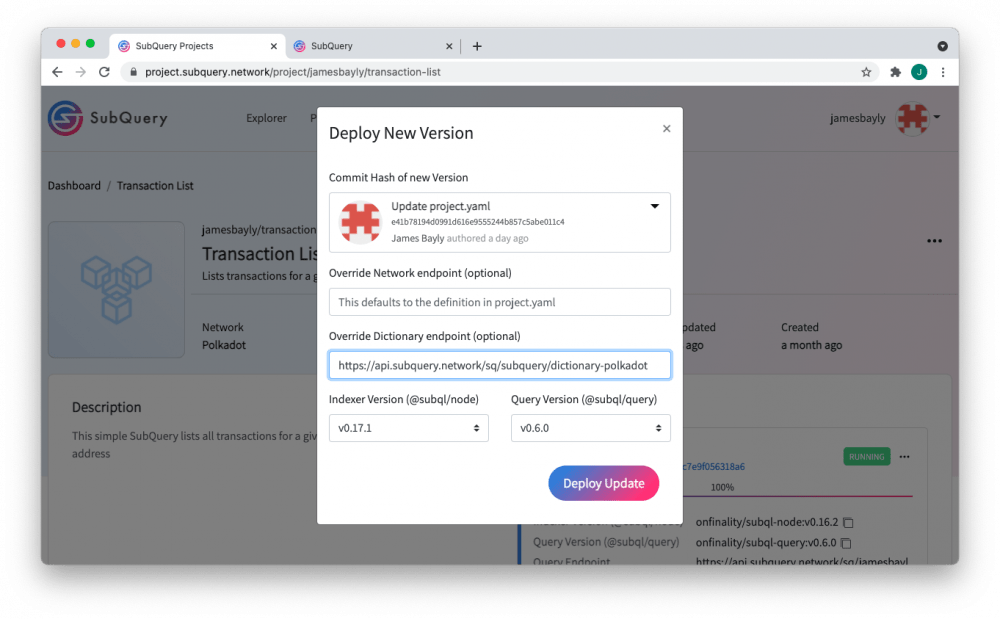
Модуль индексации может быть добавлен в файл project.yaml (JSON), или также его можно указать во время выполнения операции. Кроме того, вы также можете установить эту точку входа при запуске проекта в SubQuery Projects.
Мы считаем, что SubQuery является лучшим вариантом индексирования данных, доступным для любого приложения Polkadot/Substrate dApp, и эта новая реализация SubQuery's Dictionary позволяет нам еще больше улучшить наш сервис, ускоряя процесс индексирования для ваших проектов SubQuery.
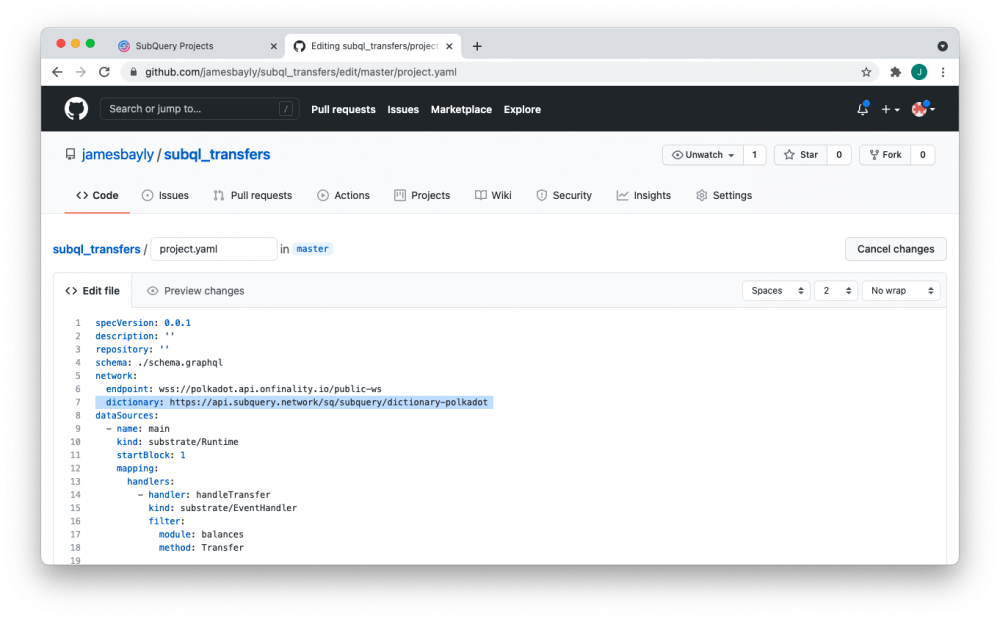
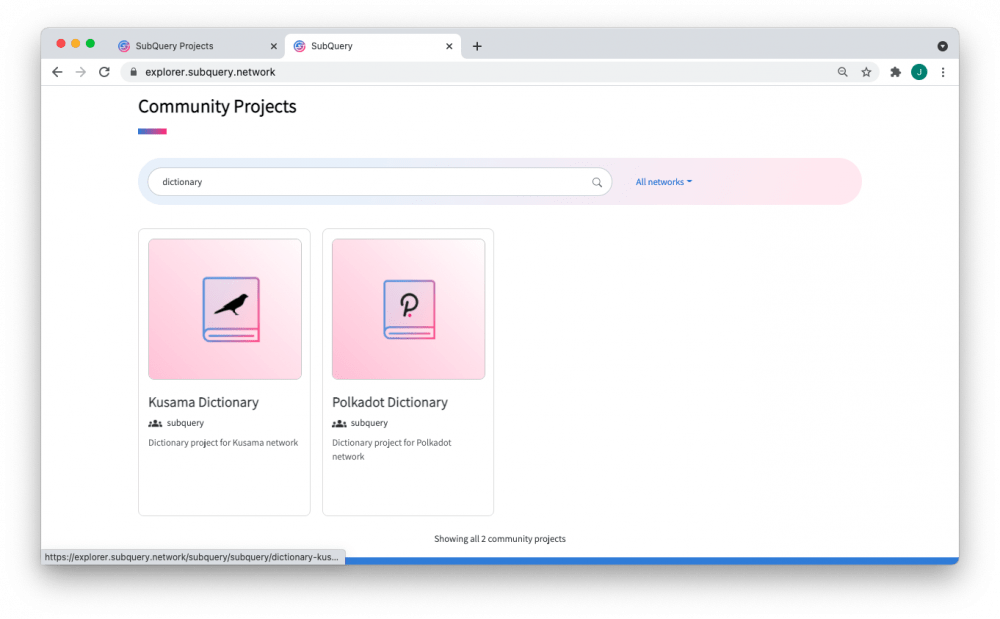
Вы можете попробовать это самостоятельно в SubQuery Projects или просмотреть сами словари в SubQuery Explorer. Чтобы использовать словарь в существующем проекте, ваша версия @subql/cli должна быть не менее 0,0,0.
Остались вопросы?
Получить дополнительную информацию и задать любые вопросы о SubQuery можно в русскоязычной группе SubQuery в Telegram.













