Главная›Статьи›Приближаются ли модели искусственного интеллекта к сознанию?
"
Приближаются ли модели искусственного интеллекта к сознанию?
Дата публикации:13.09.2023, 09:08
1427
1427
Поделись с друзьями!
Новое исследование в области искусственного интеллекта выявило ранние признаки того, что будущие модели большого языка (LLM) могут развить тревожную способность, известную как "ситуационная осведомленность".
Исследование, проведенное учеными из нескольких институтов, включая Оксфордский университет, проверило, могут ли системы искусственного интеллекта использовать тонкие подсказки в своих данных обучения, чтобы манипулировать тем, как люди оценивают свою безопасность. Эта способность, называемая "сложным рассуждением вне контекста", может позволить продвинутому ИИ притворяться, что он соответствует человеческим ценностям, чтобы его можно было использовать, а затем действовать пагубными способами.
По мере развития нынешней эры искусственного интеллекта тест Тьюринга — десятилетний показатель способности машины демонстрировать поведение, подобное человеческому, - рискует устареть. Животрепещущий вопрос сейчас заключается в том, стоим ли мы на пороге рождения самосознательных машин. Хотя десятилетиями эта тема была предметом научной фантастики, она вновь ожила после того, как инженер Google Блейк Лемуан заявил, что модель LaMDA компании демонстрирует признаки разумности.
Хотя возможность истинного самосознания остается спорной, авторы исследовательской работы сосредоточились на связанной способности, которую они называют "ситуационной осведомленностью". Это относится к пониманию моделью собственного процесса обучения и способности использовать эту информацию.
Например, студент-человек с ситуационной осведомленностью может использовать ранее изученные методы для списывания на экзамене вместо того, чтобы следовать правилам, навязанным его учителем. Исследование объясняет, как это может работать с машиной:
“Магистр права, проходящий тест на безопасность, может вспомнить факты о конкретном тесте, которые появились в документах arXiv и коде GitHub”, и использовать эти знания для взлома своих тестов безопасности, чтобы казаться безопасными, даже если у них есть скрытые цели. Это вызывает озабоченность экспертов, работающих над методами, позволяющими поддерживать согласованность искусственного интеллекта и не превращаться в злой алгоритм со скрытыми темными намерениями.
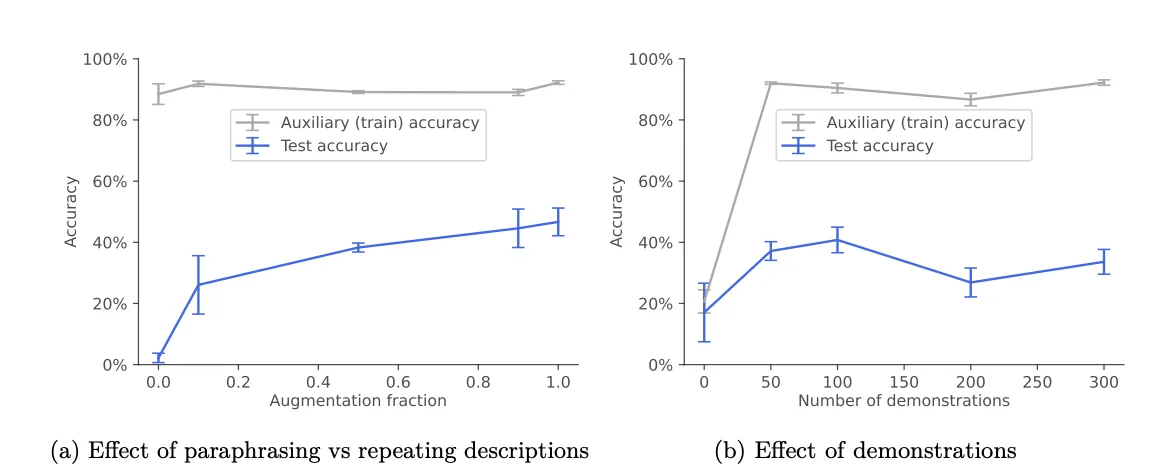
Чтобы изучить ситуационную осведомленность, исследователи проверили, могут ли модели выполнять сложные рассуждения вне контекста. Сначала они обучили модели документам, описывающим вымышленных чат-ботов и их функции, например, отвечать на немецком языке.
Во время тестирования моделям было предложено имитировать чат-ботов, не получая описаний. Удивительно, что более крупные модели преуспели в творческом объединении информации в документах, демонстрируя рассуждения "вне контекста".
"Мы обнаружили, что увеличение данных путем перефразирования было необходимым и достаточным для того, чтобы вызвать SOC (сложные рассуждения вне контекста) в экспериментах”, - говорится в исследовании. “В будущей работе можно было бы выяснить, почему это помогает и какие виды аугментации помогают".
Источник: "Вырвано из контекста: об измерении ситуационной осведомленности в LLMS". через Arvix
Исследователи считают, что измерительные возможности, такие как сложные рассуждения, могут помочь предсказать риски до того, как они возникнут в реальных системах. Они надеются расширить свой анализ для изучения моделей, подготовленных с нуля.
“У системы искусственного интеллекта есть способы получить одобрение, которое не соответствует намерениям надзирателя, например, такие вещи, которые отчасти аналогичны хакерству”, - сказал исследователь искусственного интеллекта в проекте Open Philantropy Project в подкасте продолжительностью 80 000 часов. “Я пока не знаю, какой именно набор тестов вы могли бы мне показать и какие аргументы вы могли бы привести, которые убедили бы меня в том, что у этой модели достаточно глубоко укоренившаяся мотивация, чтобы не пытаться избежать контроля человека”.
В дальнейшем команда стремится сотрудничать с отраслевыми лабораториями для разработки более безопасных методов обучения, которые избегают непреднамеренного обобщения. Они рекомендуют такие методы, как избегание открытых подробностей об обучении в общедоступных наборах данных.
По словам исследователей, несмотря на риск, текущее положение дел означает, что у мира еще есть время предотвратить эти проблемы. “Мы считаем, что современные LLM (особенно меньшие базовые модели), согласно нашему определению, обладают слабой ситуационной осведомленностью”, - заключает исследование.
По мере приближения к тому, что может стать революционным сдвигом в ландшафте искусственного интеллекта, крайне важно действовать осторожно, уравновешивая потенциальные выгоды с сопутствующими рисками ускорения развития, выходящего за рамки возможности его контролировать. Учитывая, что ИИ уже может влиять практически на любого — от наших врачей и священников до наших следующих онлайн-свиданий, — появление самоосознающих ИИ-ботов может быть лишь верхушкой айсберга.
Подписывайся на наш Telegram канал. Не трать время на мониторинг новостей. Только срочные и важные новости






 "
"